(Please download source code from here.)
Transformer (and attention architecture used in Transformer) is one of the most successful state-of-the-art (SOTA) and proven neural network architecture, which was originally developed for language processing, and it can also be applied to several other sequential modeling – such as, time-series forecasting, computer vision (see Swin Transformer, Vision Transformer, or Data-Efficient Image Transformer), and analyzing other sequence modalities.
In this post, I’ll show you two examples of deep reinforcement learning (RL) with self-attentions and Transformers.
The first one is based on Gated Transformer-XL (GTrXL) architecture, in which visual attention is applied in order to track the object (target) in the motion. The second one is Decision Transformer architecture, in which Transformer is used to predict next actions in the manner of sequence.

Note : See here for the architecture and source code of Transformers in LLMs. (In this post, I assume that you have already known Transformers.)
1. Gated Transformer-XL (GTrXL) architecture in Minecraft
About This Example (Overview)
In this example, my RL agent learns to chase and attack the randomly spawned pigs in Minecraft game.
This agent is not generalized for other Minecraft biomes. To simplify example, all pigs (the targets) are spawned in Minecraft’s flat world, and the agent just chases these spawned pigs.

Figure : Trained Agent (agent’s view)
In order to run my Minecraft agent in RL, I have used Project Malmo which is a modded forge Minecraft for reinforcement learning.
In Project Malmo, we can use statistical observations (such as, player’s position, the distance of some entity, etc), but I have just trained with only visual information (frames) and its rewards. (This example tracks the motion with only visual information.)
Note : If you are new to Project Malmo, see this example (tutorial) of Minecraft lava maze training (in which, I have simply used DQN with built-in CNN).
Attention in Visual Recognition
The main part in Transformers for capturing contexts of sequence is self-attention architecture.
As this paper says, “important property of human perception is that one does not tend to process a whole scene in its entirety at once”. This is the motivation for bringing attention in visual understanding in motion.
For instance, let me assume that you focus on something what you see.
You won’t recognize the snapshot of that frozen scene. Instead, you will remind the trajectory of scenes (multiple frames in sequence) to understand what happens, while you focus on the targets.
Self-attention mechanism helps an agent to decide this sequential contexts in visual recognition.
![]()
In this example, I have applied the following GTrXL (Gated Transformer-XL) model, which is implemented in RLlib library.
Shortly, this model is the gated version of canonical Transformer.
In this architecture, in order to prevent degradation problems (vanishing problems) in networks, GRU (Gated Recurrent Unit) layer is applied instead of generic residual connection. (See here for the implementation of GRU (Gated Recurrent Unit) architecture.)

(From : Stabilizing Transformers for Reinforcement Learning)
Let’s go dive into details.
Firstly, the frame pixels (i.e, vision information) are encoded into 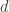
All incoming inputs for Transformer are then separated into 3 parts – query (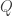
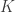

In self-attention layer, the current input is queried and then scored to all inputs (keys) including historical states obtained by RNN.
Finally, the attention embeddings are fed into gating layer (GRU layer) to prevent degradation problems (vanishing problems) in deep networks.
This entire process is repeated subsequently in multiple layers, and the final output is then used for the action distribution’s inputs.

where I assume the following properties in this picture :
- The number of attention dimension (d) = 32
- The number of attention head (h) = 1
- The number of input sequence (T) =3
- The number of memory sequence (Tau) = 4
- The number of Transformer layers (N) = 5
In the actual example (in GitHub), I have set the following properties. :
- d = 32
- h = 2
- T = 20
- Tau = 50
- N = 1
Note (*1) : The formal Transformer architecture also includes the information for positional distance in scores, called positional encoding. In this example, the sinusoidal position with
sin()andcos()function is used for positional encoding.
In order to simplify, I have skipped the positional encoding in above picture.
See here for details about positional encoding.
The advantage of this architecture (especially, compared with Decision Transformer) is that we can integrate this architecture with the existing state-of-the-art (SOTA) model-free learners for agents – such as, reinforcement learning algorithms or imitation learning algorithms. Because it just optimizes the policy 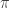
In this example, I have used PPO for RL algorithm to learn the action.
PPO-Penalty (not PPO-Clip) is used for training, and Kullback-Leibler divergence (KL-divergence) is evaluated for avoiding the large updates. (See here how PPO algorithm optimizes the action.)
Note : Not only policy model but also value model in PPO uses above Transformer layer. (The policy and value shares Transformer network.)
In shared network, the coefficient (ratio) between policy loss and value loss is then an important parameter. (See here for policy loss and value loss.)
Work with continuous action
My agent only learns the direction (the turning degrees) to walk.
In general, applying continuous actions in RL is challenging, but I haven’t discretized the target’s action and used the continuous action, Box(low=-1.0, high=1.0), in this example.
For your reference, I briefly show you how I have configured the action space as follows.
- To keep resilience for scaling the values of tensors, I didn’t use the built-in action distribution for continuous action – Gaussian distribution with 2 inputs (mean and log standard deviation) or Beta distribution. (See my post for the bad effects of large training and large coefficients.)
Instead, I have configured my own custom Gaussian distribution, in which it uses 2 inputs (and
), and both are used only for mean value in Gaussian.
These 2 inputs give the following L2-normalized (square-normalized) mean value and it then leads toBox(low=-1.0, high=1.0). As you can see below,keeps constant, as long as these values keep same ratio. (Note that it’s not continuous on the point
, and I then also added the bias to prevent the agent from starting at this point.)

See here for source code of this custom action distribution. - In regard to log standard deviation (
) in Gaussian, I have used a fixed value,
(in which,
) in order to simplify the training. (Because it needs much more training iterations to learn the standard deviation.)
We must take care to correctly define log std deviation, because it has a trade-off between exact exploitations and rich explorations. - In order to prevent my agent from keeping turn, I have initialized the coefficients of weights and bias in my custom vision layer (CNN) as small random norm values.
However, we must take care to correctly define this value, because this might lead you to be less optimized for parameters if it’s so small. (In the worst case, it will keep the same outputs in convolution layers and then not trained forever…)

Result
Here I’ll show you the transition of reward’s mean in the trained agent. (See below.)
In this example, each training iteration occurs every 4,600 samples (train_batch_size=4600), in which each mini-batch updates parameters with 128 mini-batch samples (sgd_minibatch_size=128).
Over 90,000 parameters are trained in this model.
The agent rapidly learns, and chases pigs within some distance from agent on around 120 training iterations. In the subsequent iterations (over 150 training iterations), the agent learns to chase pigs in more far distance from agent, and is getting more accurate. (It’s performant than simple convolutions without attention.)
![]()
The repository (see here) also includes the saved checkpoint which I have trained in my machine, and you can then restore (and run) this trained agent. (You can soon try and see the motion of this trained result.)
2. Decision Transformer architecture in Atari Pong
Finally, I’ll briefly show you another Transformer architecture in reinforcement learning, Decision Transformer.
Decision Transformer is an offline reinforcement learning algorithm based on autoregressive sequential modeling, which simply outputs the optimal actions by leveraging a causally masked Transformer.
Such like predicting tokens with Transformers in language processing, Decision Transformer can predict the next actions after the training with expert’s behaviors.
Note : Unlike previous example, Decision Transformer requires the offline data (expert data) collected in advance.
There also exists a challenge to apply Decision Transformer to online finetuning after offline pretraining in the same architecture (which is the modification for enabling sample-efficient online finetuning). See here for details.
In reinforcement learning, the current state is given and the agent will then take an appropriate action depending on the state. If the action is succeeded, the positive reward will be returned to the agent. (See here for the fundamentals of reinforcement learning.)
In Decision Transformer architecture, the sequence in Transformer consists of the repetition of multiple tokens – the desired rewards (so called, return-to-go (rtg) rewards), states, and actions. (See below note for the return-to-go rewards.)
By the autoregressive analysis in Transformer, the next token – especially, the next action – will then be predicted (generated) with causal proceeding tokens.

Note : The return-to-go rewards (rtgs) is the sum of future rewards.

Let’s go dive into details.
Given a dataset of offline trajectories, each tokens (i.e, rtgs, states, and actions) are firstly embedded into vectors with same dimensions.
The embedded tokens are then fed into decoder-only Transformer to generate next tokens.
During the training, only the next actions are used for computing loss and optimization. (The output of states and rtgs are ignored in optimization. The states and rtgs are only used for inputs.)

As you know, today’s large language models (LLMs) are so much matured Transformer architecture.
The advantage of this architecture is to bring these well-matured architectures into learning of the sequence of trajectories in very natural way.
The official repository provides the complete example of Decision Transformer to play Atari Pong game, but it needs much time and resources to run and experiment.
I have then reduced and generated small example for training Decision Transformer to play Atari Pong game. (See here.)
In this example, minGPT is used for decoder-only Transformer.

Reference :
Python Tutorial for Reinforcement Learning algorithms
https://github.com/tsmatz/reinforcement-learning-tutorials
Minecraft Pig Chase with GTrXL – source code
https://github.com/tsmatz/minecraft-rl-pigchase-attention
Atari Pong small example with Decision Transformer – source code
https://github.com/tsmatz/decision-transformer
NLP (Language) Tutorials (including Attention and Transformer implementation)
https://github.com/tsmatz/nlp-tutorials
Categories: Uncategorized

1 reply »